MirageLSD: The First Live-Stream Diffusion AI Video Model

Today, we are releasing MirageLSD, the first Live-Stream Diffusion (LSD) AI video model that inserts your imagination into any live video feed — it is the difference between watching magic on a screen and making magic yourself. We are also showing a demo of Mirage, our platform (website today, iOS/Android coming next week), powered by the MirageLSD model.
Unlike other AI video models with 10+ second delays and 5-10s clips, Mirage transforms infinite video streams in realtime (<40ms response time). Mirage is our second model after Oasis (the viral "AI Minecraft"), took roughly half a year to build, and required solving cutting-edge math challenges and writing efficient GPU assembly code. For the technical deep dive, check out the details below.
Mirage is day one. Next come a variety of additional video models, audio, emotions, music—we're building the platform that turns all our senses into portals. Today, you can play with Mirage on any device to teleport your surroundings, games, and films to new universes with different laws of physics and magic.
Throughout the summer, we will have regularly releases of model upgrades and additional features, including facial consistency, voice control, and precise object control. We look forward to sharing this with you and hope you will stay tuned on our channels: X, Reddit, Discord
With Love,
Decart
Technical Report
What if AI could imagine in real-time - forever?
MirageLSD is the first system to achieve infinite, real-time video generation with zero latency. It is built on our custom model called Live Stream Diffusion (LSD), which enables frame-by-frame generation while preserving temporal coherence. Unlike prior approaches, LSD supports fully interactive video synthesis - allowing continuous prompting, transformation, and editing as video is generated.
Current video models can’t go past 20-30 seconds of generation without suffering from severe quality degradation due to error accumulation. They often require minutes of processing for just a few moments of output. Even the fastest systems today that approach real-time typically generate video in chunks, introducing unavoidable latency that breaks interactive use.
Using MirageLSD, it is now possible to create a new variety of interactive experiences that weren’t previously possible before.
Introduction

Error accumulation leads to rapid quality deterioration, effectively limiting the output length of previous auto-regressive video models.
To generate video in real-time, a LSD has to operate causally - producing each frame based only on frames that came before it. This auto-regressive structure ensures continuity but introduces a serious flaw: error accumulation. Each frame inherits the imperfections of the last. Small errors accumulate leading to rapid loss of quality until the frames are incoherent.
Previous video models either generate a fixed short length video [5,6,7], or use auto-regressive generation but suffer from loss of quality and are thus limited to short outputs [4,8].
Enabling LSD required solving two challenges that have not previously been addressed together in a single system.
1. Achieving Infinite Generation
.png)
MirageLSD is the first video generation model able to generate infinitely long videos.
The auto-regressive nature of the model leads it to accumulate errors, effectively limiting the length of its outputs. To enable infinite auto-regressive generation:
- We build upon the Diffusion Forcing [1] technique, which allows per-frame denoising.
- We introduce history augmentation, where the model is fine-tuned on corrupted input history frames. This teaches it to anticipate and correct for input artifacts, making it robust to the drift common in auto-regressive generation.
Together, these make LSD the first model to generate video infinitely without collapse - stable, promptable, and consistently aligned with both scene and user input.
2. Achieving Real-Time Performance
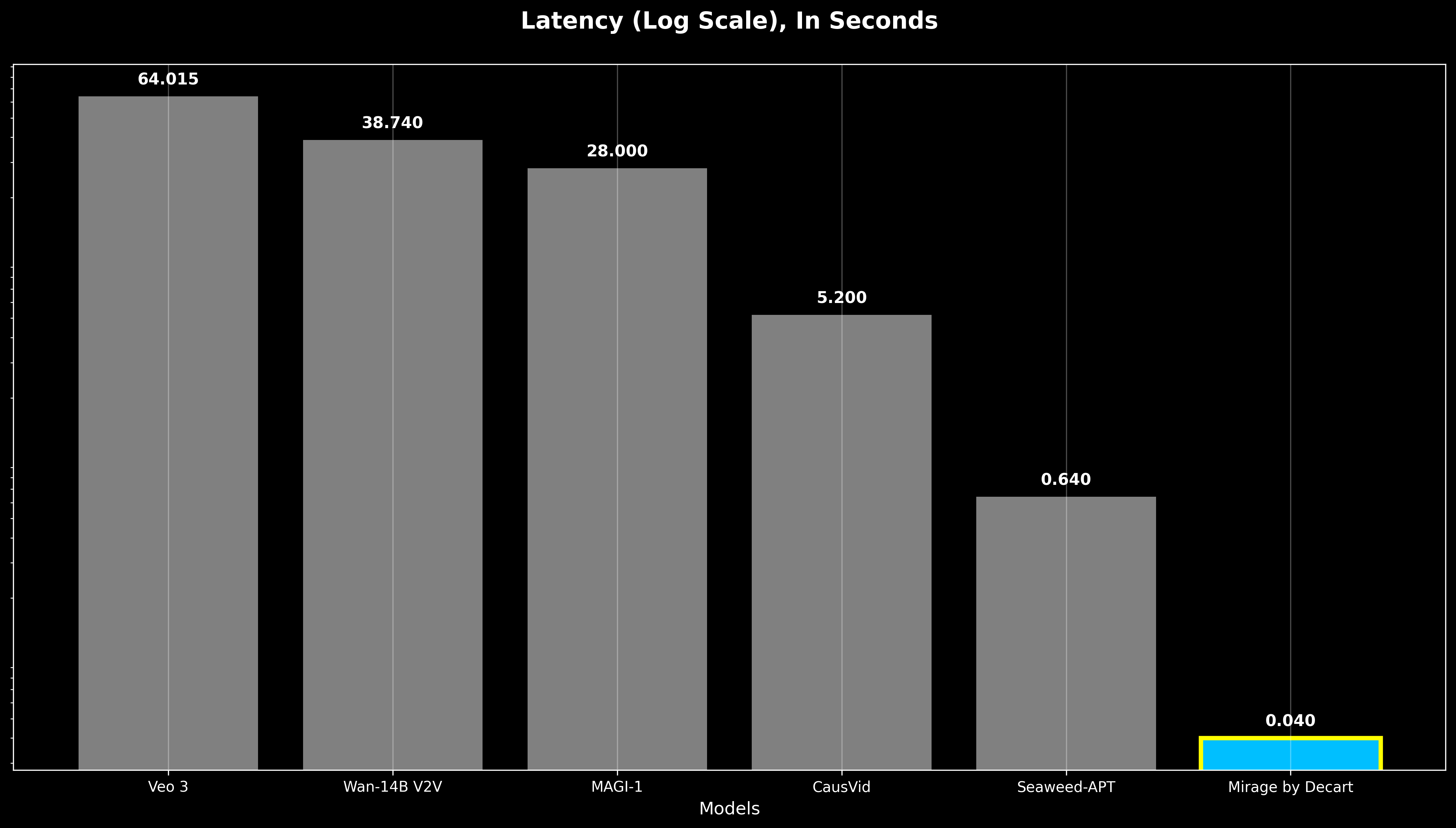
Responsiveness is defined as the worst case response latency, even previous Auto-regressive models are more than 16X slower to respond than MirageLSD, making real-time interactions impossible.
Real-time generation requires each frame to be produced in under 40 milliseconds, in order to not stand out to the human eye. We achieve this by:
- Designing custom CUDA mega kernels [11] that minimize overhead and maximize throughput.
- Building upon shortcut distillation [12] and model pruning to cut the amount of computation needed per frame.
- Optimizing the model architecture to align with GPU hardware for peak efficiency.
Together, these techniques yield a 16× improvement in responsiveness over prior models, enabling live video generation at 24 FPS.
Recent efforts in video generation have advanced visual quality and clip duration, but most systems still lack one or more of the following: interactivity, low latency, and temporal stability.
Fixed-length models like MovieGen, WAN, and Veo [5,6,7] generate high-quality video clips, but their non-causal design and full-clip inference introduce latency and prevent real-time interaction or extension beyond predefined lengths.
Auto-regressive models such as CausVid, LTX and Seeweed-APT [4,10,8] generate longer sequences by conditioning each chunk on prior outputs. While this improves scalability, chunked inference still limits responsiveness and suffers from error accumulation, capping generation length and ruling out true interactivity.
Controllable generation methods, including ControlNet [8] and LoRA-based adapters [2], enable targeted editing and style transfer but require offline fine-tuning and are not suited to live, frame-by-frame prompting.
Our prior system, Oasis [3], demonstrated the first real-time causal generation within a constrained domain. Live Stream Diffusion (LSD) extends this to open-domain, promptable video with zero-latency, real-time speed and indefinite stability - a combination not achieved by prior work.
MirageLSD can turn physical real-world objects into mythical items in the stream — turn a stick fight into a lightsaber show
Diffusion models generate images or video by gradually denoising random noise through a series of steps. In video generation, this typically involves producing fixed-length clips all at once, which helps maintain temporal consistency but introduces latency. Some systems attempt to improve flexibility by generating chunks of frames sequentially in what is known as auto-regressive generation. However, each chunk must still be completed before the model can respond to new input, limiting interactivity and real-time use.
.png)
LSD takes a different approach. It generates one frame at a time, using a causal, auto-regressive structure where each frame is conditioned on previously generated frames and the user prompt. This enables immediate feedback, zero-latency interaction, and video generation that can run continuously without a predefined endpoint.
At each time step, the model takes in a window of past generated frames $(F_{i-2}, F_{i-1}, F_i)$, the current input frame $(I_{i+1})$, and the user-defined prompt $(P)$. It then predicts the next output frame $(F_{i+1})$, which is immediately fed into the next step in the sequence.
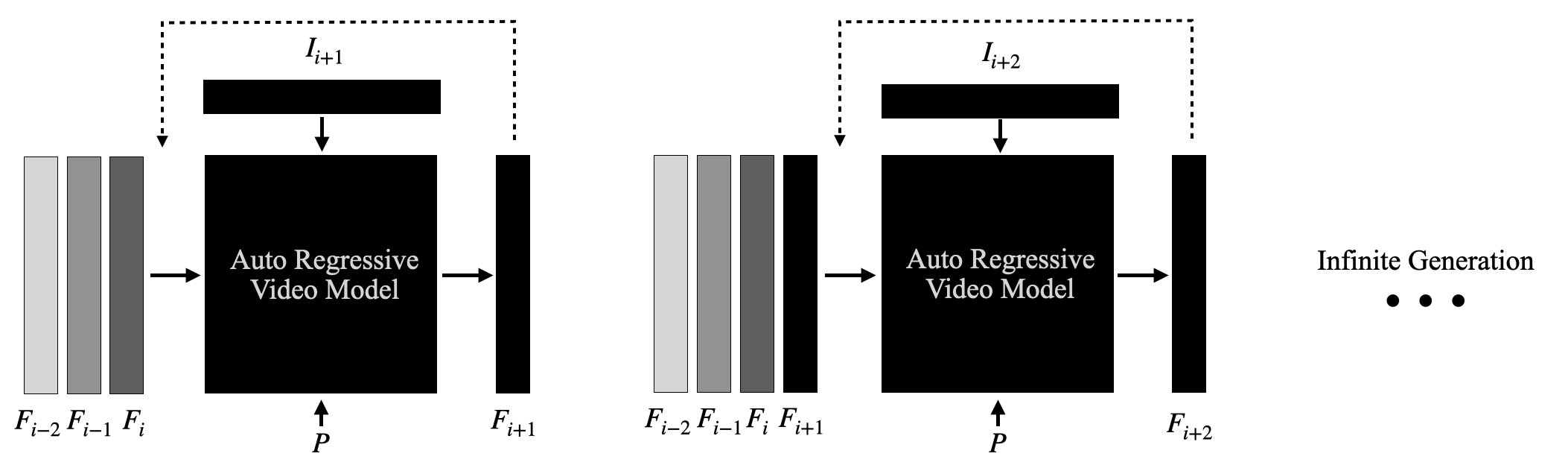
This causal feedback loop enables LSD to maintain temporal consistency, adapt continuously to motion and content, and generate infinite video sequences while respecting the user’s prompt in real time.
In addition, it enables the LSD to respond instantly to input - whether that’s a text prompt or a change in the video - with zero latency. It’s what makes real-time editing and transformation possible.
To enable this, we use Diffusion Forcing - a pretraining method where each frame of a training video is independently noised. This teaches the model to denoise individual frames without relying on access to the full video context, making frame-by-frame generation possible.
The Hidden Problem: Error Accumulation
In unstable generation, without our error-resistant training and inference techniques, output quality rapidly deteriorates - as subtle generation flaws compound, the quality degrades as the model rapidly drifts from the data it was trained on.
Since each frame depends on the last, small errors can quickly add up. A shadow slightly out of place, a texture slightly wrong - these imperfections compound over time, pulling the model further from the data it was trained on. After just a few seconds, most models begin to drift causing incoherent outputs.
This issue - known as error accumulation - is the main reason previous models couldn’t generate video beyond a handful of seconds without degrading.
We solve this by fine-tuning the model to expect and correct artifacts in its input history. We do this by augmenting the input history frames while training with artifacts that simulate those that the model might generate in a teacher forcing setup. We then indicate to the model during inference that it should expect the history frames to be inaccurate. Together, these strategies mitigate the problem and enable us to generate infinite videos.
Under the Hood #2: Achieving Zero-Latency Real-Time Speed
A key requirement of LSD is the ability to generate each frame independently within a strict latency budget - under 40 milliseconds - to support sustained 24 FPS generation. This imposes significant challenges both in terms of model design and systems execution.
First, high-quality diffusion models are computationally intensive. They typically require large parameter counts and multiple iterative denoising steps per frame. Each step involves a full forward pass through the model, resulting in a high volume of floating-point operations (FLOPs) per frame.
Second, unlike offline generation pipelines, LSD must meet strict per-frame latency constraints. These constraints are fundamentally at odds with how modern GPUs are architected: they prioritize high throughput and large batch execution over low-latency, single-sample inference. Challenges include kernel launch overhead, limited opportunity for overlapping computation across sequential layers, and increased sensitivity to memory transfer latency, particularly in multi-device setups.
To address these issues, we employ a three-pronged optimization strategy:
- Hopper-optimized Mega Kernels:
we optimize the model execution for the NVIDIA Hopper GPU architecture by utilizing several emerging techniques similar to MegaKernels [11] to minimize the per-layer model latency under small batch size restrictions. We further integrate GPU-GPU communication at the core of these kernels in order to guarantee seamless communication between the devices that is masked by the computational operations. - Architecture-aware Pruning:
We find that a tight integration of model architecture with systems-level optimizations can reduce the number of FLOPs required per model execution while benefiting from better overall tensor-core utilization through advanced techniques that tune the parameter sizes to specific GPU constants and further exploit sparsity in the model weights using dedicated hardware support. These pruning approaches aim to both adapt the model architecture according to the underlying GPU architecture in order to maximize the utilization of the GPU, as well as reduce the global number of FLOPs required by fine-tuning the model to be resilient to the removal of various parameters. - Shortcut Distillation:
To reduce the number of diffusion steps required for generation, we apply shortcut distillation methods [12], training smaller models to match the denoising trajectory of larger teacher models. This approach significantly cuts the number of model evaluations per frame while preserving output quality and temporal consistency. Importantly, it avoids introducing new artifacts or drift during long sequences.
Together, these techniques allow us to reduce the latency of high-fidelity video diffusion from several seconds per clip to under 40 milliseconds per frame - achieving true real-time, interactive generation.
While MirageLSD achieves real-time, promptable, and stable video generation, several challenges remain open. First, the system currently relies on a limited window of past frames. Incorporating a longer-term memory mechanism could improve coherence over extended sequences, allowing for more consistent character identities, scene layout, and long-term actions. Additionally, while MirageLSD supports text-guided transformations, precise control over specific objects, spatial regions, or motion remains limited. Integrating structured control signals - such as keypoints or scene annotations - may enable finer-grained, user-directed edits in live settings.
Further work is needed to improve semantic and geometric consistency, particularly under extreme style shifts. While MirageLSD maintains local consistency well, extreme style shifts can occasionally distort object structure or layout. Addressing this requires stronger mechanisms for content preservation under prompt-driven guidance. These enhancements would extend MirageLSD’s reliability and usability across broader applications, from live editing tools to open-ended generative media systems.
@misc{mirage2025,
title = {MirageLSD: Zero-Latency, Real-Time, Infinite Video Generation},
author = {Decart AI},
year = {2025},
note = {Technical Report},
howpublished = {\url{https://mirage.decart.ai/}},
}
Resources
[1] Diffusion Forcing: Next-token Prediction Meets Full‑Sequence Diffusion – Boyuan Chen, Diego Martí Monsó, Yilun Du, Max Simchowitz, Russ Tedrake & Vincent Sitzmann (NeurIPS 2024 / ICML 2025). arXiv:2407.01392
[2] LoRA: Low‑Rank Adaptation of Large Language Models – Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang & Weizhu Chen (ICLR 2022). arXiv:2106.09685
[3] Oasis: A Universe in a Transformer (Interactive Realtime Open‑World AI Model) – Decart & Etched (2024). Project page
[4] Diffusion Adversarial Post‑Training for One‑Step Video Generation (Seaweed‑APT) – ArXiv 2501.08316 (2025). arXiv:2501.08316
[5] Wan: Open and Advanced Large‑Scale Video Generative Models – ArXiv 2503.20314 (2025). arXiv:2503.20314
[6] Veo 3: Latent Diffusion Audiovisual Model – DeepMind Tech Report (2025). Veo‑3 Tech Report PDF
[7] MovieGen: A Cast of Media Foundation Models – Meta AI (2024). arXiv:2410.13720
[8] CausVid: From Slow Bidirectional to Fast Autoregressive Video Diffusion Models – Wei Yin et al. (CVPR 2025). arXiv:2412.07772
[9] Adding Conditional Control to Text‑to‑Image Diffusion Models (ControlNet) – Lvmin Zhang, Anyi Rao & Maneesh Agrawala (ICCV 2023). arXiv:2302.05543
[10] LTX‑Video: Realtime Video Latent Diffusion – Natan HaCohen et al. (ArXiv 2501.00103, Dec 2024). arXiv:2501.00103
[11] Mega Kernels – “No Bubbles” – Stanford Hazy Research blog (May 27, 2025). Stanford Hazy Research
[12] One‑Step Diffusion via Shortcut Models – Frans, Danijar Hafner, Sergey Levine & Pieter Abbeel (ArXiv 2410.12557, Oct 2024). arXiv:2410.12557